Vector Search & RAG: A Practical Mental Model for Semantic and Conversational Search
Vector search, semantic search, and RAG are often used interchangeably. This article introduces a simple mental model to distinguish these search types, techniques, and tools to hopefully help you get a clearer idea of when to use each.


Introduction
The goal of this article is to give you a high-level overview of how Vector Search and RAG work, and shows the basic tools used to implement semantic and conversational search (what is all that?, you might ask. Stick with me, we’ll get to it).
I won’t go deep into details or trade-offs. Instead, I want to provide a broad mental model that helps you reason about different search types and tools, and then decide where to go deeper depending on your needs.
For that I will break this article into 3 parts, this one being the first one
- Basic concepts and mental model
- Implementing Semantic Search with OpenSearch
- Implementing Conversational Search with OpenSearch and Open AI API
Basic concepts and mental models
In order to understand Vector Search it is helpful first to understand searching at the type level and at the technique level and how they correlate to each other. The diagrams below help to map the definition of different searching types and techniques and when to use what technique for each type. Hopefully the diagram helps to make a faster connection without having to use a long description for each.
Search Types
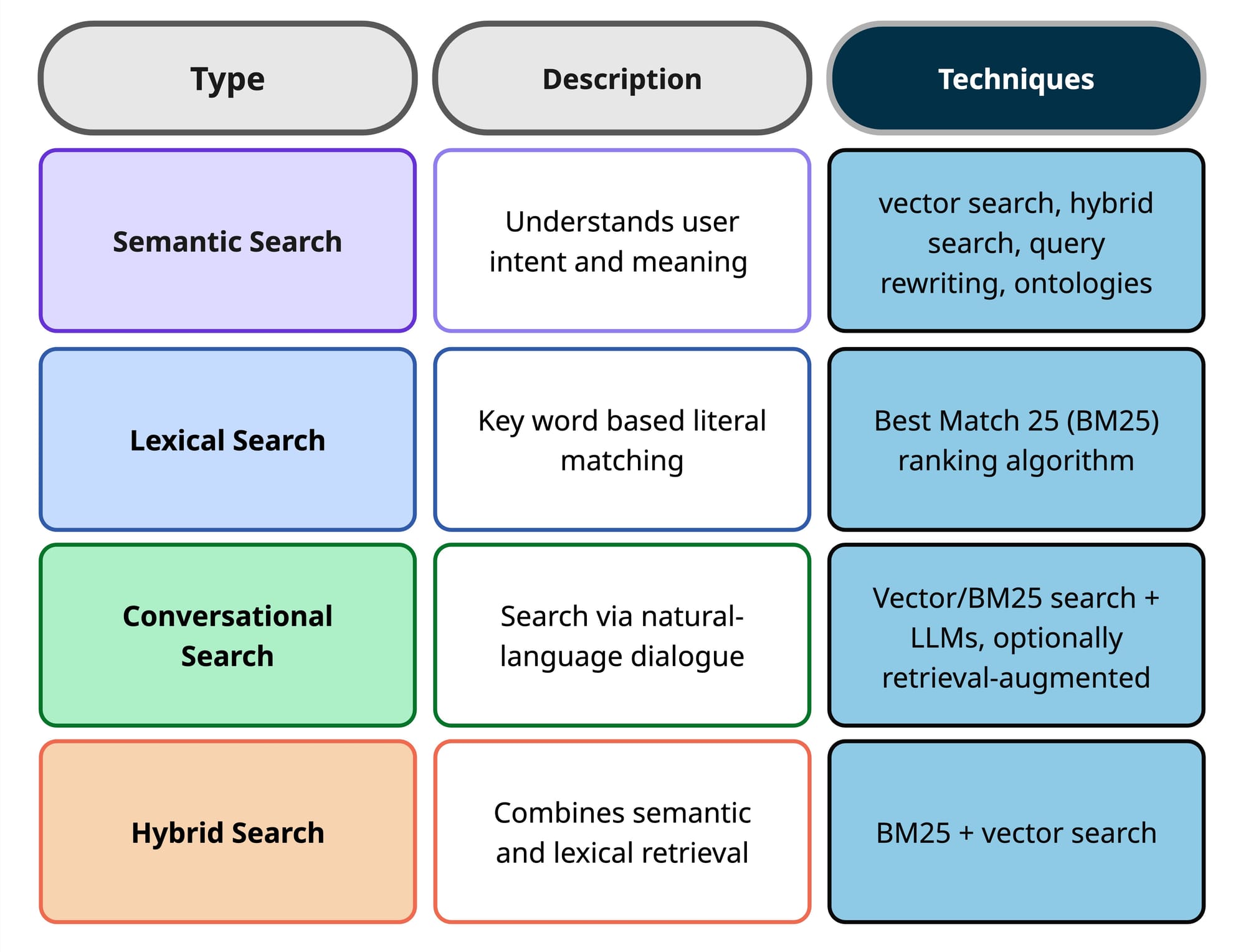
Search Techniques
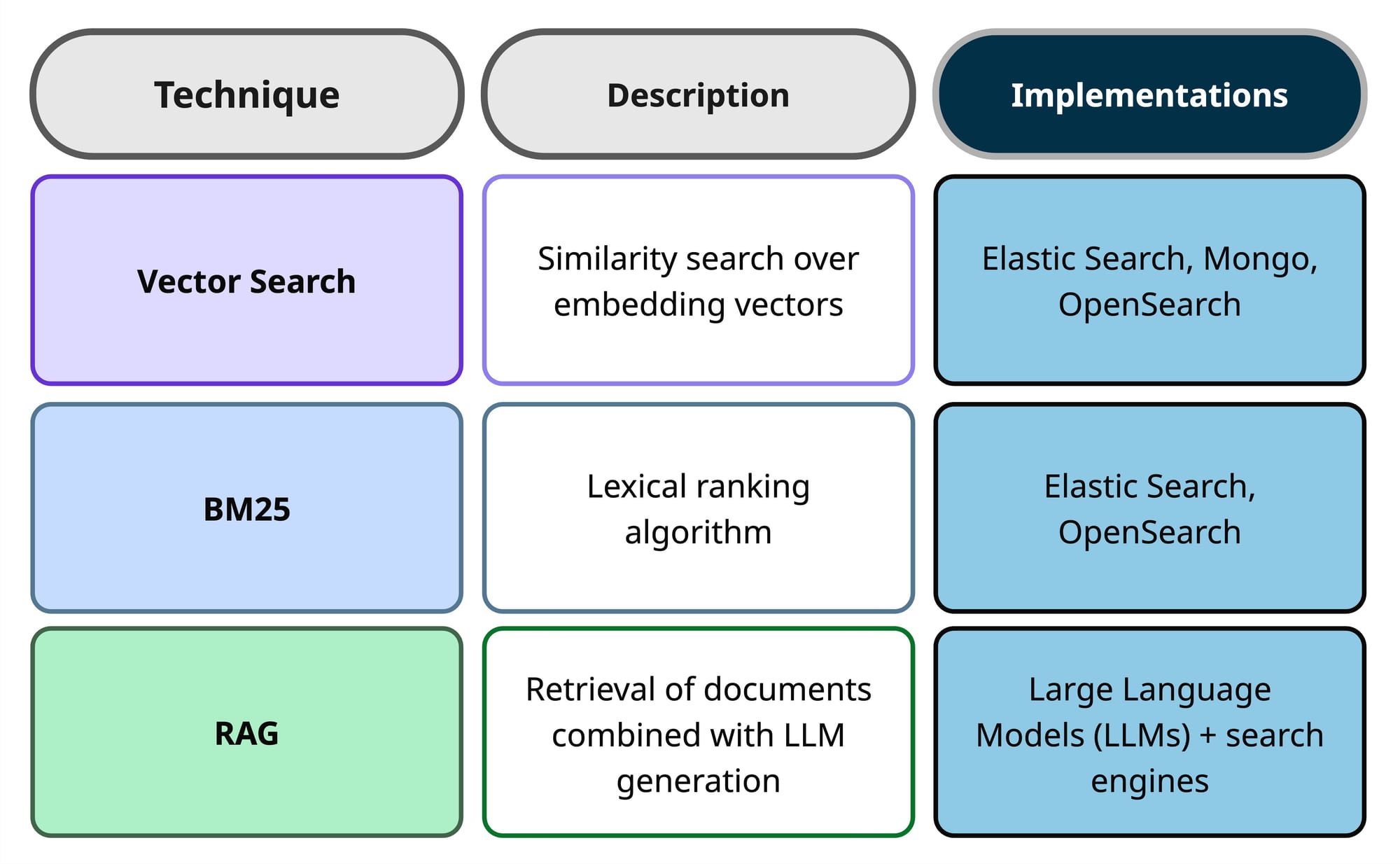
Now that we understand the different types, techniques and tools, I would like to go a bit deeper on understanding the core concepts for some of them.
Vector Search
In the previous table we had a brief description of what Vector Search, and before jumping to explaining how it works in practice, I would like to introduce some key concepts that would be helpful to talk about Vector Search more in detail.
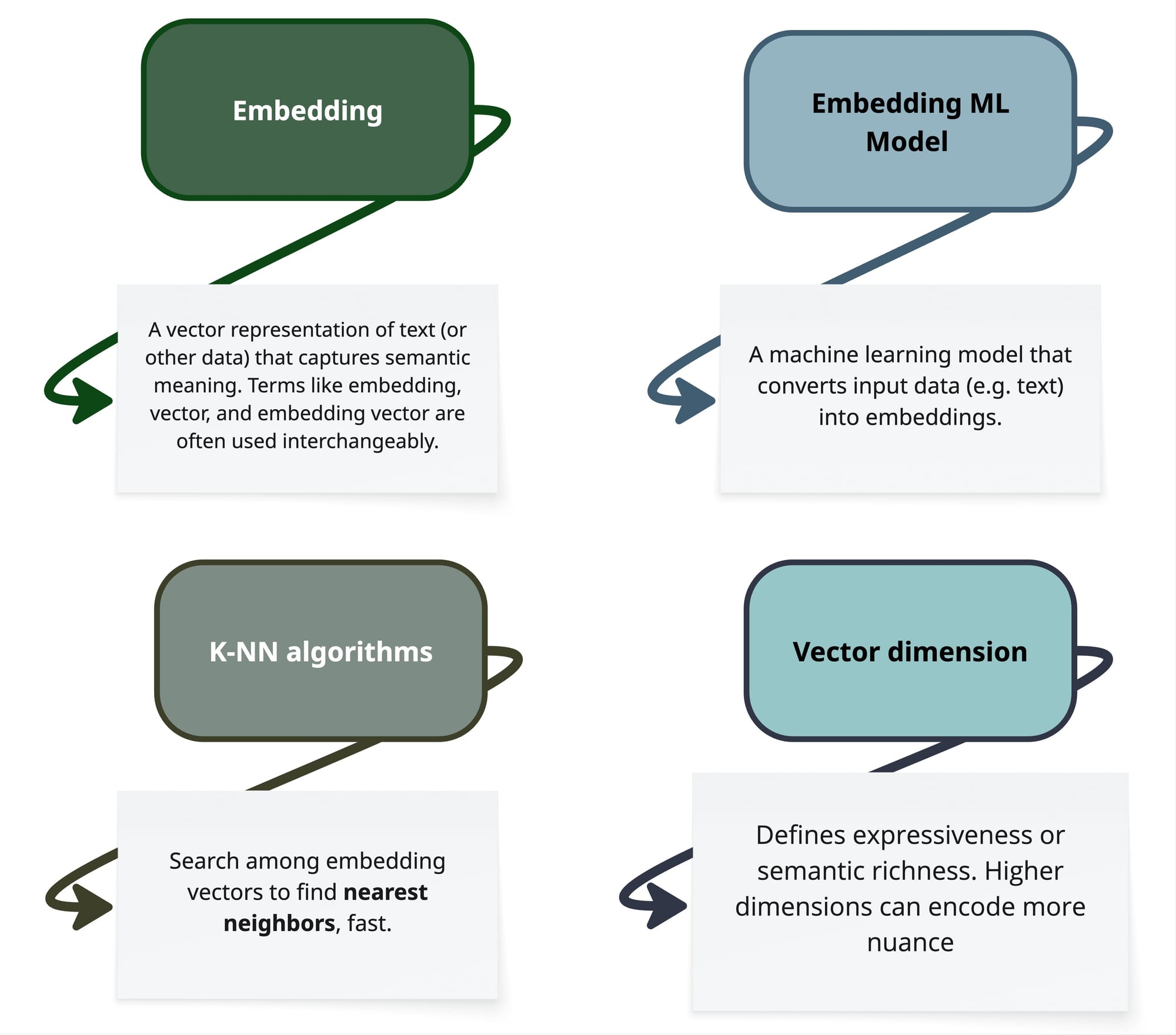
How does it work in practice?
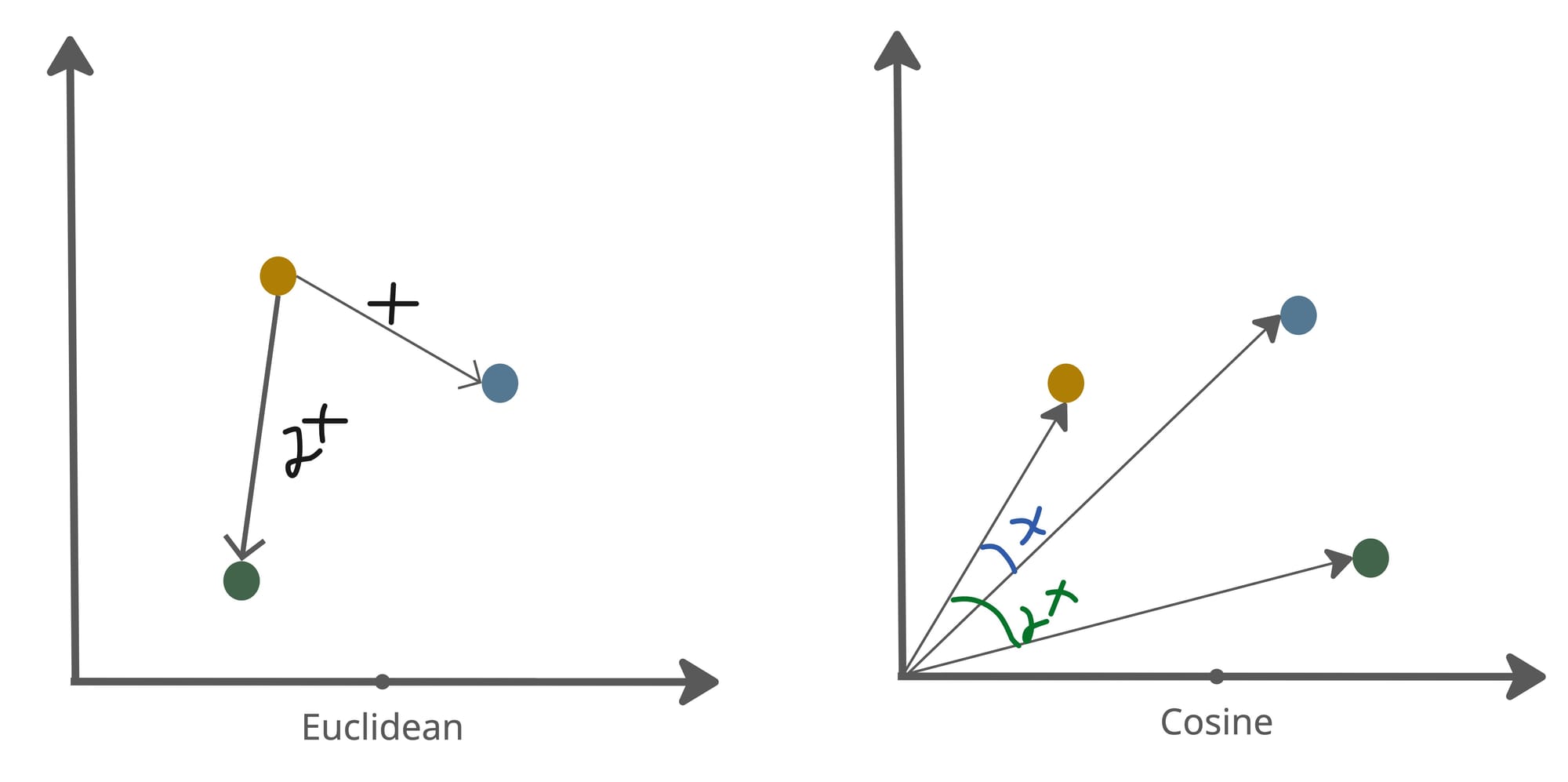
With these concepts in mind, the following is a mental model oversimplifies and might leave you with some questions which hopefully will get clarified in the next section.
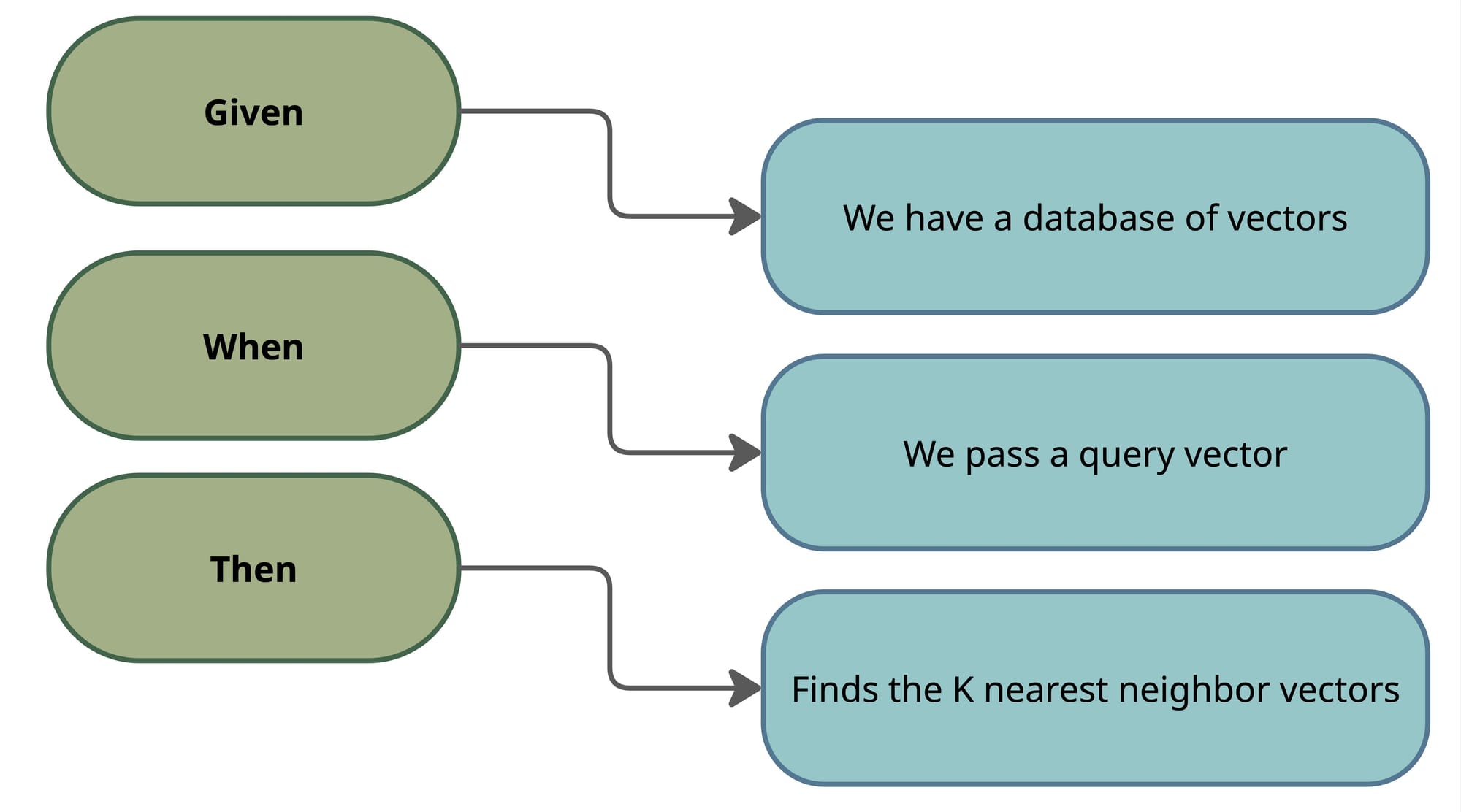
- K vectors with the smallest distance (Euclidean)
- K vectors with the largest cosine similarity
Semantic Search
As we saw earlier we use Vector Searching as a technique we use to implement Semantic Search, and in order to achieve this, we have two important steps, the indexing phase and the actual search phase.
The next two diagrams will give you a better picture of how everything is pulled together when a user makes a search.
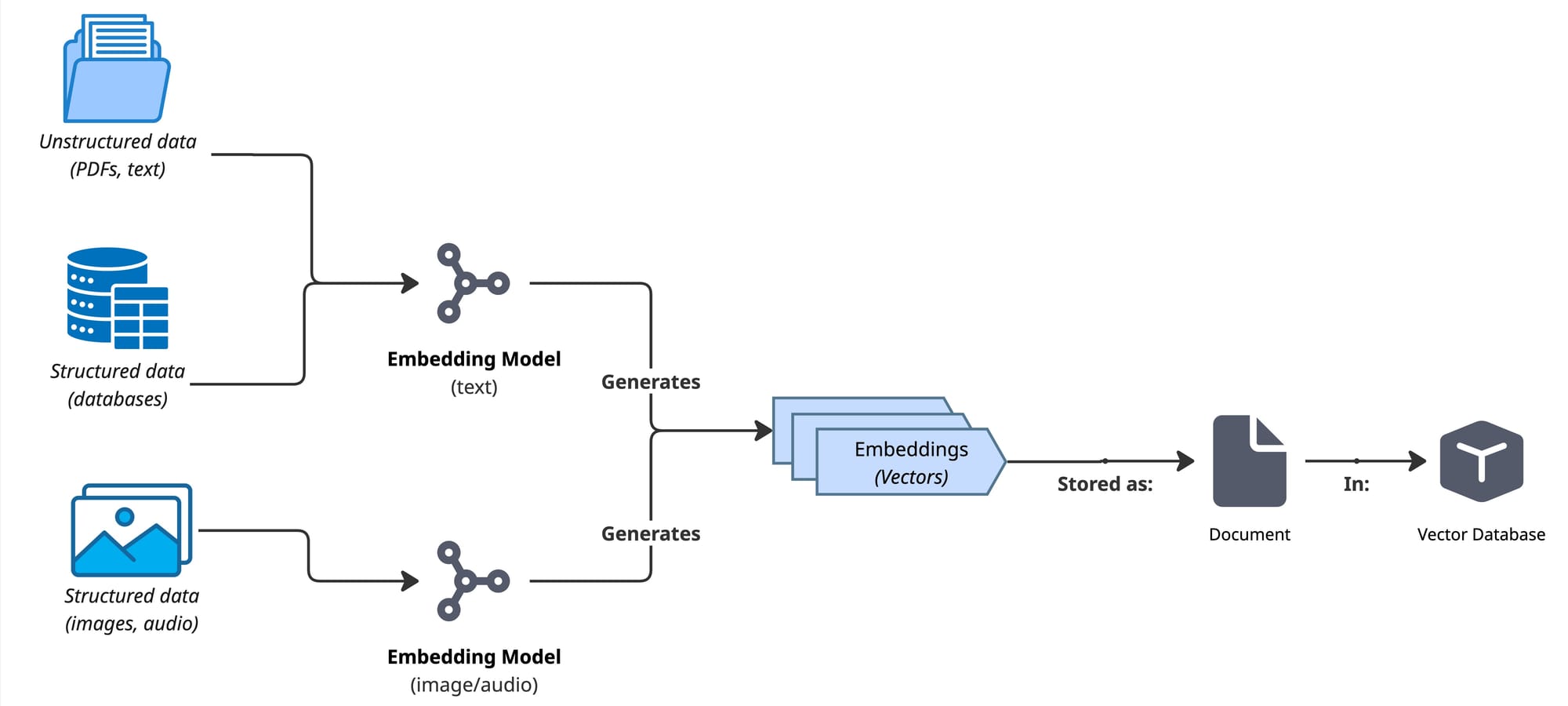
Indexing phase
In this phase the goal is to take all the data that we have available for searching, whether is structured or unstructured and create embeddings (vectors with meaning) and stored them in a database that supports storing these vectors.
Search phase
In this phase, the first step is to convert the use query in an embedding too, so we can compare it against with the other embeddings we already have in our database.

RAG
Finally, lets talk about RAG briefly. There’s plenty of information out there regarding this topic so I don’t want to go into details that very likely others are better at explaining it than me. Instead of describing and going into theory, I would like to provide you a mental model on how RAG is used in the context of conversational searching and using as baseline what we know so far about Vector searching.
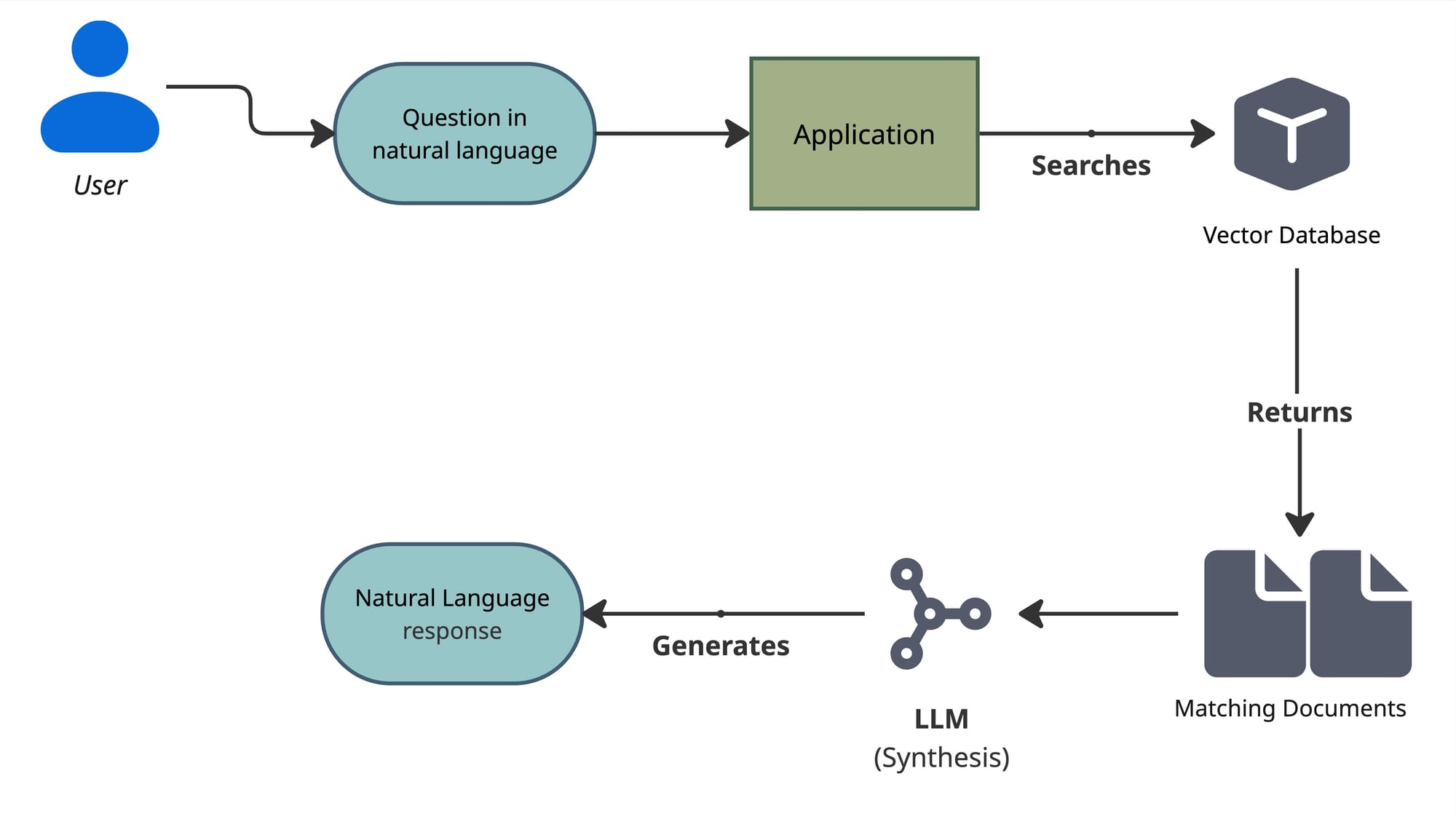
The LLM
- Compares multiple documents (which are result of a vector search)
- Extracts relevant details
- Explains trade offs
- Summarizes
- And answers why and how in natural language
Next
I hope these mental models give you a clear idea of the what is the difference between all the different searching terms out there and help you choose the right search strategy for your particular use case.
In the next chapters, we will explore two practical examples: