Avoiding nested streams in Spring Webflux & Kotlin
Reactive programming can be very exciting and fun to learn but it also can be challenging if you are used to more imperative programming.


Reactive programming can be very exciting and fun to learn but it also can be challenging if you are used to more imperative programming.
One of the most common advices I've found when working with reactive code is to keep things simple, however even with all the cool features that Spring Webflux provides, sometimes simplicity is hard to achieve.
In this article we will review at one of the common challenges when writing reactive code (nested flatMaps/Maps) and what we can do to make them more readable.
The problem
Imagine that you have to build a Product object with the data from 3 different repositories. Your data model for the product looks like this:
data class Product(
@Id val id: Int,
val code: String,
val description: String,
val sizes: List<Size> = emptyList(),
val colors: List<Color> = emptyList()
)
Notice that sizes and colors have a default value of empty list because that data comes from two different database tables.
You also have a Service class that contains the function to get and build the product object by reading from 3 different repositories. The interesting part is that you need the results of two of the repositories to build the final product so one natural approach is nesting the result so at the end you can get access to the colors and the sizes.
fun getProductById(productId: Int): Mono<Product> {
return productRepository.findById(productId)
.flatMap { product ->
colorRepository.findByProduct(productId).collectList()
.flatMap { colors ->
sizeRepository.findByProduct(productId).collectList()
.map { sizes ->
product.copy(colors = colors, sizes = sizes)
}
}
}
}
This might be ok but as time passes and multiple people start contributing, code like this can become complex pretty quick and therefore difficult to read.
This is also a simplified version of the problem. I've seen situations where multiple calls need to be done and even by breaking things down into different functions it is still difficult to manage.
Avoiding nesting
So what can we do in a situation like this? One option is to use functions like zipWith and zipWhen which allow you to combine the results of two different streams and return the results as a Tuple. With such approach you could do something like this:
fun getProductById(productId: Int): Mono<Product> {
return productRepository.findById(productId)
.zipWith(colorRepository.findByProduct(productId).collectList())
.map { it.t1.copy(colors = it.t2) }
.zipWith(sizeRepository.findByProduct(productId).collectList())
.map { it.t1.copy(sizes = it.t2) }
}
This is not bad, although still can use some improvement to make more clear that the first component of the Tuple (it.t1) is the Product object.
But indulge for a moment and let me go a bit further to demonstrate situations in which the above code is not possible and you have to call the zip functions one after another. In those situations you might have some code like this:
fun getProductById(productId: Int): Mono<Product> {
return productRepository.findById(productId)
.zipWith(colorRepository.findByProduct(productId).collectList())
.zipWith(sizeRepository.findByProduct(productId).collectList())
.map {
// In this case it is a Tuple2 containing another Tuple2:
// Tuple2<Tuple2<Product, Colors>, Sizes>
val product = it.t1.t1
product.copy(colors = it.t1.t2, sizes = it.t2)
}
}
In this case we end up with nested Tuples, a Tuple2 that contains a simple object and another Tuple2 (yeah more nesting, we got rid off one but we get another).
One possible solution would be resorting to local variables to try to make the contents of the Tuple more obvious, like shown in the code above.
Deconstructing tuples
So how do we take advantage of the zip functions without having to declare new variables to keep things clear?
For this case we can use a couple Kotlin's features to improve readability:
First, we are going to use extensions to add functionality to the Tuple classes, by introducing a function to flatten a Tuple2, that is to convert a Tuple2 object that contains another Tuple2 into a Tuple3 that contains 3 simple objects:
fun <S, D, U> Tuple2<Tuple2<S, D>, U>.flatten(): Tuple3<S, D, U> =
Tuples.of(t1.t1, t1.t2, t2)
The code above might be a bit tricky so lets make an example to show what would be the result of applying this flatten function:
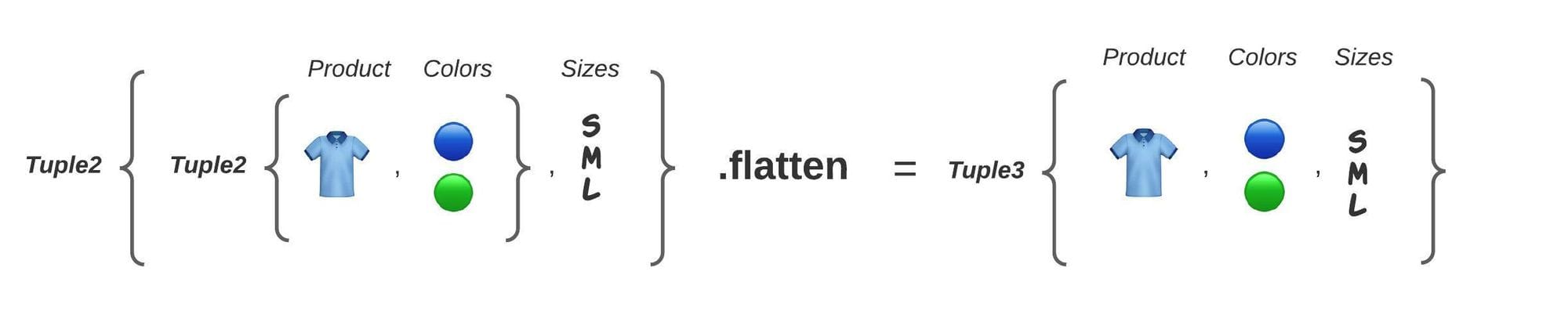
Then we are going to add 3 functions that allow us to get the contents of each component of a Tuple3.
operator fun <T1, T2, T3> Tuple3<T1, T2, T3>.component1(): T1 = t1
operator fun <T1, T2, T3> Tuple3<T1, T2, T3>.component2(): T2 = t2
operator fun <T1, T2, T3> Tuple3<T1, T2, T3>.component3(): T3 = t3
The 3 above extension functions is what will enable us to deconstruct the Tuples inside each block by allowing us to write something like this:
map { (product, colors, sizes) ->
product.copy(colors = colors, sizes = sizes)
}
Instead of this:
map {
// In this case it is a Tuple3<Product, Colors, Sizes>
val product = it.t1
product.copy(colors = it.t2, sizes = it.t3)
}
Final result
Finally, we can import and use our extension functions by first flattening the nested Tuple and then by deconstructing its components to make them more distinct.
fun getProductById(productId: Int): Mono<Product> {
return productRepository.findById(productId)
.zipWith(colorRepository.findByProduct(productId).collectList())
.zipWith(sizeRepository.findByProduct(productId).collectList())
.map { it.flatten() }
.map { (product, colors, sizes) -> product.copy(colors = colors, sizes = sizes) }
}
In my experience zip functions work pretty well when combining only 2 streams, you could live without deconstructing the Tuple because is easier to distinguish the components but even there you could benefit from deconstruction. In that scenario the code will look like this:
fun getProductById(productId: Int): Mono<Product> {
return productRepository.findById(productId)
.zipWith(colorRepository.findByProduct(productId).collectList())
.map { (product, colors) -> product.copy(colors = colors) }
.zipWith(sizeRepository.findByProduct(productId).collectList())
.map { (product, sizes) -> product.copy(sizes = sizes) }
}
To deconstruct Tuples with only two components (Tuples of type Tuple2) you don't need to write your own extensions like we did for Tuple3, instead you can just import the reactor-kotlin-extensions library to your project.
// If you are using Gradle, add this line to your gradle dependencies file
implementation("io.projectreactor.kotlin:reactor-kotlin-extensions")
Other alternatives
There are always other alternatives. One library that I have used in the past to accomplish similar goals, is Komprenhensions, this library allows you to chain your calls by keeping things comprehensible (bad pun intended):
fun getProductById(productId: Int): Mono<Product> {
return doFlatMapMono(
{ productRepository.findById(productId) },
{ _ -> colorRepository.findByProduct(productId).collectList() },
{ _, _ -> sizeRepository.findByProduct(productId).collectList() },
{ product, colors, sizes -> product.copy(colors = colors, sizes = sizes).toMono() }
)
}
Of course with the addition of libraries, there are always risks but each project is unique and you are always the best to decide what option best fits your needs.
Conclusion
This article is a bit more opinionated than previous posts, so please take everything with a grain of salt. There's always different ways to produce the same results and they all can be valid and all have their advantages and disadvantages.
What do you think? What other ways you think we can avoid nested calls?
Photo by Federico Enni on Unsplash